豆瓣电影分类排名爬取:
今天晚上复习了一下python学习之百度翻译页面爬取
复习成果已经写在上一个博客了
这接下来就是requests模块学习之豆瓣电影分类排名进行数据爬取
我本来以为这个学会之后就可以对豆瓣呀,网易云上面的歌曲进行爬取了
开始学习之后标题给我整了一个豆瓣电影分类排名爬取
但是还是太年轻了,原来事情没有那么简单
下面就是一边听课一边编写的代码,后面有一个错误,以及解决过程
# -*-coding=utf-8-*-
# 编写时间2021/3/28;19:28
# 编写:刘钰琢
import requests
import json
if __name__=='__main__':
#url=''#制定url
#params={
# 'kw':kw
#}#在get函数中可以时制定kw关键字
#headers={
# 'User-Agent':''#对应ua检测的一个反反爬策略
#}
#response=requests.get(url=url,kwargs=kwargs,)
#接下来就是requests模块练习之爬取豆瓣电影分类排行
#import 模块时候已经添加完成
#指定URl
url='https://movie.douban.com/j/chart/top_list?'#问好后面的都是携带的参数i,我们可以使用字典的形式去添加参数
#这一步就是要添加参数,记得要用字典的形式去添加参数
param={
'type': '24',
'interval_id':'100:90',
'action':'' ,
'start': '1',#从豆瓣库中的第几部电影去取
'limit': '20',#表示一次请求取出的个数时20
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.63'
}
response=requests.get(url=url,params=param,headers=headers)
#这个时候我们就获取到了响应对象 这个响应对象的格式时一个json的数据类型
lst_data=response.json()
fp=open('./douban.jdon','w',encoding='utf-8')
json.dump(lst_data,fp=fp,ensure_ascii=False)
print('over!!!')这个错误吧就是
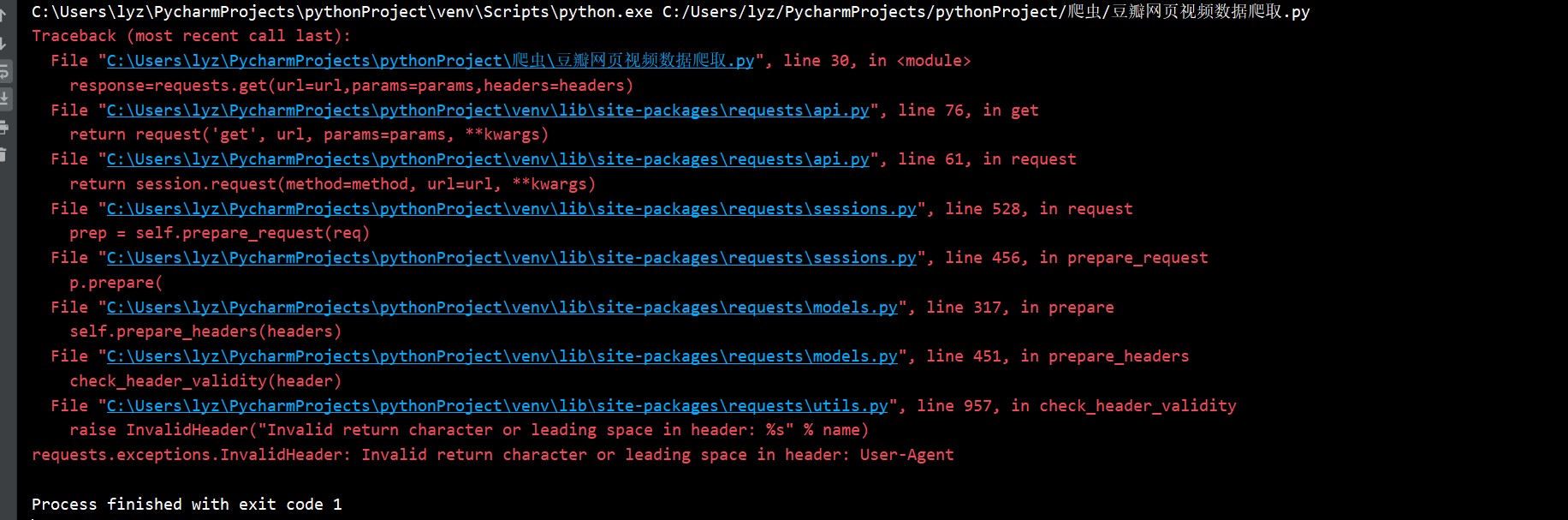
经过对比老师的代码,我看了好多地方都发想一样的
后来我就再次打开抓包工具 中间的user_agent后面的内容是不能有空格的所以才会有这个问题,删除空格之后

最后也是成功了,但是不知道怎么啦,爬取的内容是无法分布到多行的有往后边多看了一点发现要用
https://www.bejson.com/ 这个去个格式化json代码最后也是成功显示