下面就是我晚上复习百度翻译破解的代码:
import requests
import json
post_url='http://fanyi.baidu.com/sug'
kw_post=input()
#post请求参数处理,同get当中的那个params之中他是一样的都是用来传递参数的
data={
'kw':kw_post
}
#在请求参数之前要进行ua伪装
headers={
'User-Agent':'这里就先不写了,回去在补上'
}
#请求发送
response=requests.post(url=post_url,data=data,headers=headers)
#获取返回内容
#response.txt=...这个酒会返回的是字符串类型的数据
#response.json=...这个会返回的是obj (如果确认相应参数数据是json类型的,才可以使用json类型)
#这个主要是从抓包工具中的headers中的Response headerszhongde content.typs:就可以看出来返回值的类型
#只有这个返回值类型是json时才能使用response.json去获取返回职中的内容
#要是用text就指挥室有返回一些字符串编码 切记
dic_obj=response.json()
print(dic_obj)#直接输出去验证爬取的内容是否时对的
filename=kw+'.json'
fp=open('./filename','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascli=False)
print('over,网页已经爬取')下面是以dog为例子代码的运行结果
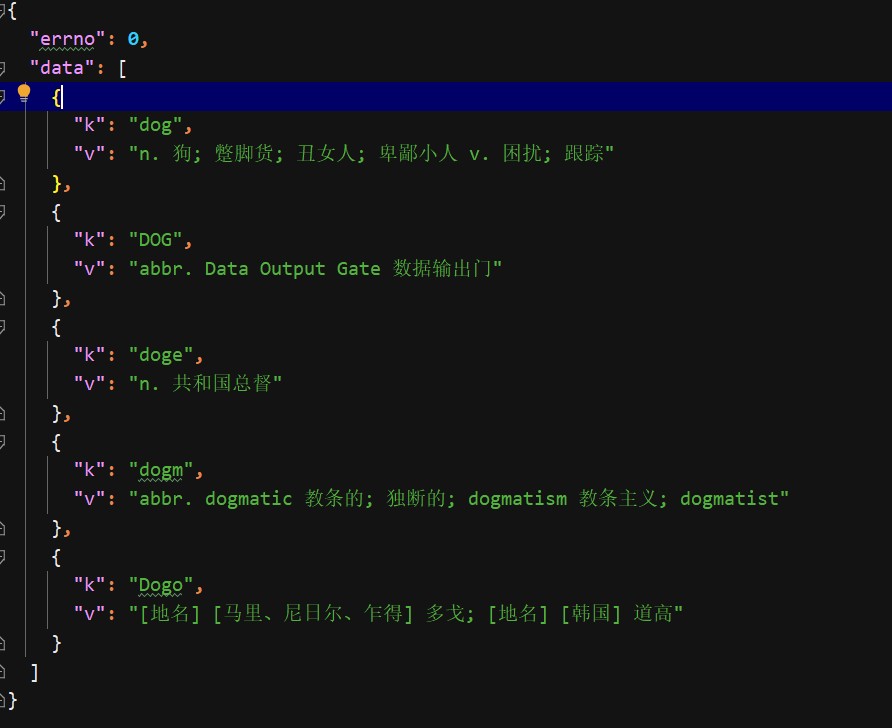
如果返回出来的json代码是在一行的话直接ctrl+a 在Ctrl+alt+L
对代码进行换行处理
如果在控制台输出的话直接点击换行按钮进行换行
在代码最后面会有
json.dump(dic_obj,fp=fp,ensure_ascii=False)这一行应该是想
with open(filename,’w’,encoding=’utf-8’)as file
file.write(dic_obj)我感觉应该是一样的
并没有太大的区别
至于那个json中的ensure_ascii=False就是不加输出就会是和你用text导出的时候是一样的都是都是一些ascii码
所以这个是和encoding=’utf-8’是差不多一个意思吧



