今天学习了爬取药品线管总局中的企业详细信息
第一步就进行了网站的直接爬取代码如下:
# 时间:2021/4/5;16:20
# 编写人:刘钰琢
# 药品监管总局
import requests
url='http://scxk.nmpa.gov.cn:81/xk/'
headers={
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'
}
response=requests.get(url=url,headers=headers)
page_text=response.json()
with open('药监总局.html',"w",encoding='utf-8')as file:
file.write(page_text)这一部分直接显现了
经过多次对比发现只有ID是不一样的
http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=5eb10afc74a2462c8e86652ec8d90a48
所以用这个ID值可以从首页的ajax请求中的json串中获取
http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById
这个是在网站的许可证详情页中抓包中找到的,而且这个URL只带了一组参数就是ID逐渐找到突破点
还发现他是一个post传参 他的URL是一样的就只是ID的只是不一样的
如果我们可以批量获取多家企业的ID后,就可以将ID和URL形成一个完整的详情页对应详情数据的Ajax请求的URL
在这之后就进行了对比以及对详情那个页面进行抓包后发现他只携带一个参数而且每一个的url是一样的这就可以进行url和参数的拼接直接去爬取到想要的企业相关的详细信息
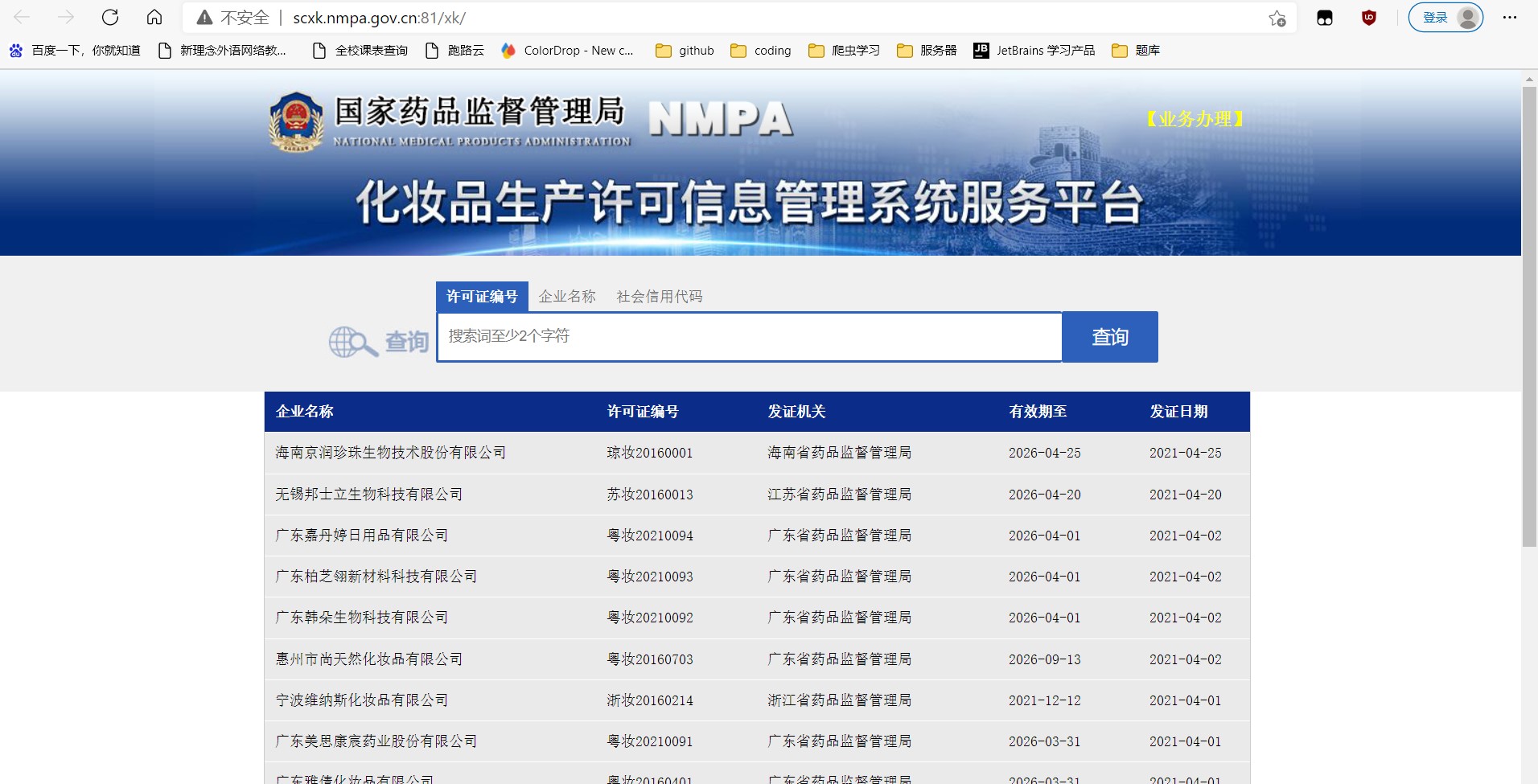
然后就是写代码了
# -*-coding=utf-8-*-
# 时间:2021/4/5;17:15
# 编写人:刘钰琢
import requests
import json
if __name__=='__main__':
url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
params={
'on': 'true',
'page': '1',#这个应该是第一页
'pageSize': '15',#一页显示了多少个数据这两个是可以修改的
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':''
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'
}
response_json_ids=requests.post(url=url,data=params,headers=headers).json()
id_lst=[]
for dic in response_json_ids['list']:
id_lst.append(dic['ID'])
#获取企业下详情数据
all_list=[]
url_inf='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_lst:
data={
'id':id
}
response=requests.post(url=url_inf,data=data,headers=headers).json()
#print(response)
all_list.append(response)
fp=open('药监局2.json','w',encoding='utf-8')
json.dump(all_list,fp=fp,ensure_ascii=False)
print("结束了!!")这第一步就是在上图2中的打开了抓包工具直接发现的之后就是在这个json数据中收集ID一共下一步使用
在接下来的企业详情页面中进行访问就可以进行爬取到要求的页面了,在json网站对相应的数据进行json解析就收集到了
企业的详情信息,致此药监局化妆品生产许可证企业信息爬取就结束了



